The NLT Labs Pipeline
One sentence in.
Demo site deployed end-to-end.
Phase 1 researches and evaluates (five analysts in parallel, Devil's Advocate stress-test, then a PE Firm verdict). Phase 2 builds and deploys the demo. A FUND verdict (pe:fund) adds the issue to the scheduled POC queue; founder retrospective + GitHub review keep humans in the loop before deploy.
What the pipeline now outputs
The pipeline is no longer abstract. Nine demos live on nltlabs.ai today — four featured here.
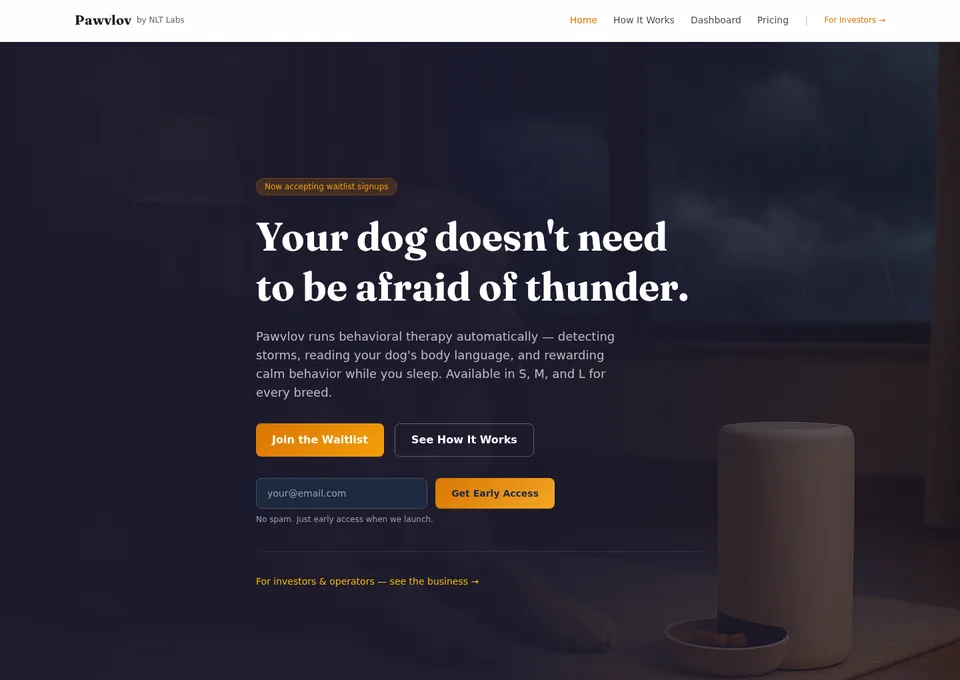
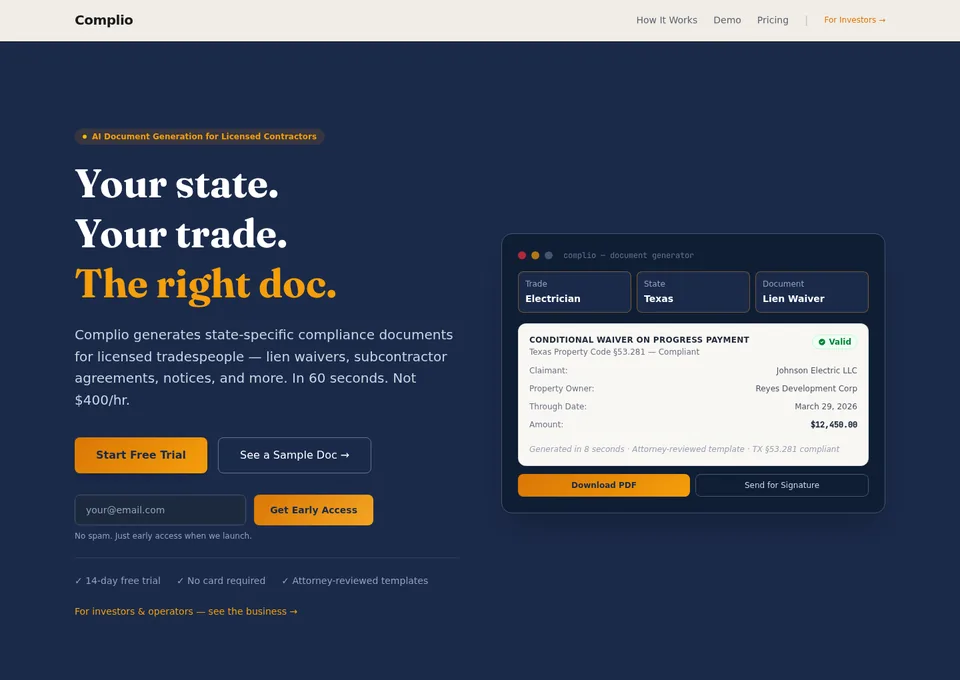
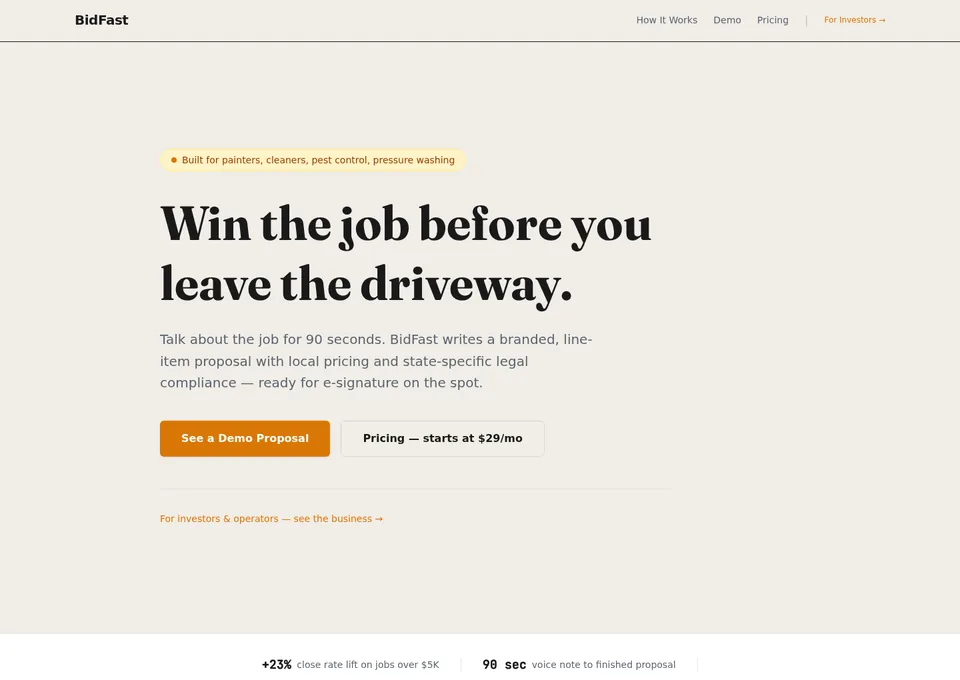
Why This Exists
The machine behind every pipeline run.
Most companies spend months and $50,000 figuring out if an idea is worth building. NLT Labs runs the same evaluation through a nine-section rubric, with forced Optimist, Skeptic, and Pragmatist lenses, then a Devil's Advocate stress-test. A FUND verdict (typically ~6+ average after the full rubric) queues the build crew for a deployed demo site with evaluation notes attached.
The key innovation is research-first. Every agent builds on real competitive data, real customer quotes from Reddit, real market evidence. Nothing is invented cold. The Creative Director runs gap-filling searches before writing a brief. The Market Researcher cites primary sources. The Competitive Analyst pulls actual Crunchbase funding data. By the time the PE Firm scores the idea, it's working with substance, not temperature.
Hardware products (when explicitly in scope, default pipeline skews software-first) get a dedicated Product Designer that thinks like an industrial designer: use scenarios, mechanism specs, electrical schematics, real BOM pricing at 1K and 10K unit volumes. All before code or 3D. The 3D render prompt is derived from the mechanism spec, not invented.
The output is a demo deployed as a two-door site: a polished consumer experience for browsers, and a single-scroll evaluation-notes page (/inside) with real market data, unit economics, roadmap, capital ask, and a contact button. Hardware POCs add a rotating 3D model, lifestyle hero render, studio render, and a downloadable Tech Specs sheet. Everything grounded in what the agents actually found.
Meet the Team
15 specialists wired into workflows/*.yaml. Each one does one job.
Software-only evaluations use fewer roles; hardware adds Product Designer. Dig Deeper is a follow-on loop, not a full-time seat on every idea.
Expands the seed into a research brief and checks scope. No scoring. Gap-fills before researchers start: missing customer pain? Pulls real Reddit threads. Thin comps? Searches pricing pages. The five analysts inherit a brief that is specific and sourced, not invented.
Finds the real market, with sources. No invented TAM numbers. Real customer voice from Reddit and reviews. Real industry data with citations.
Maps the competitive landscape with real funding data. Crunchbase raises in the space, what they built, why they raised. Grounds the PE Firm's valuation reality check.
Runs scope:deep sequential mode, not a shallow scan. Answers "can we actually build this?" The real questions: what tech, what team, what timeline, and what might blow up in year two.
Runs the numbers with primary sources required. Customer cost to acquire, lifetime value, break-even point. Broken math shows up in the PE verdict. Not as a rubber stamp.
Hunts for legal landmines with citations. Licensing requirements, data privacy exposure, liability. Primary source required. No guessing.
Before the PE write-up: attacks the thesis. Fact-checks quantitative claims, stress-tests financials, hunts hidden competitors, documents kill shots with evidence. The PE Firm reads this pass first, then owns the verdict.
The math gate. Inspects every quantitative claim across the briefs: TAM/SAM/SOM math, unit economics, contradictions between sections, missing formulas, implausible projections. Owns a broken-math hard cap that floors the PE Firm score when arithmetic is unsound. The reason "derived from cited numbers" actually means something.
The judge. Runs a nine-section Gate 1 rubric (forced Optimist / Skeptic / Pragmatist lenses), then summarizes the headline scorecard most people see: Market, Execution, Moat, and Timing, each with explicit justification.
Dig Deeper (conditional): when the PE verdict asks for more research, a targeted follow-up run answers specific questions, sometimes with a human gate, then the issue is re-scored. It does not replace the Devil's Advocate pass on a full evaluation.
Names the product, researches competitors, and writes a brief grounded in real market data. Saves a competitive-research.md with competitor table, pain points, category visual language, and differentiation angle. Every downstream agent reads it.
Hardware only. The industrial design brain. Runs 6 stages: use scenario narrative, form language rationale, mechanism spec, electrical schematics, sensory design, competitive contrast. Outputs an interactive BOM at 1K and 10K unit volumes, a three-size SKU strategy (S/M/L breed-matched dimensions, retail and gross margin per tier), and materials + regulatory cert sheet (FDA food-grade, UL94 V-0, FCC Part 15 pre-launch). The Visual Assets prompts are derived from this spec. Not invented.
Hardware only. Generates four photorealistic product renders — studio, lifestyle hero, exploded internals, and S/M/L product family — via Nano Banana (Gemini 2.5 Flash Image). An anchor-then-variant pattern locks subject identity across scenes so the dog, the device, and the room are the same across renders. Containerized agent; ships or blocks on judge scores.
Reads competitive research before touching any layout. A Visual Differentiation section is mandatory: "competitors do X, we do Y, because Z." Every layout decision is grounded in something real.
Research-first. Every line grounded in real customer pain points from the competitive-research.md. Hardware copy must match the actual mechanism. Runs at the same time as the Web Designer.
Builds the two-door site (consumer-facing + the 8-tab /inside investor brief), wires the Visual Assets renders and BomTable into the Product & BOM tab, then deploys under a custom subdomain and notifies Bill with the live link + a 1–5 star quality rating prompt. Also ships Path to Product and Tech Specs.
The Output
Not a prototype. A demo site with full evaluation notes attached.
Every FUND-verdict idea is built into all of this. The /inside evaluation-notes page alone would cost $10,000+ from a consultant.
Self-Improvement
The system improves itself.
Every deploy feeds back into the pipeline. Over time, the system gets better at predicting which ideas produce good outcomes.
After each deploy, the Provisioning Agent prompts Bill for a 1–5 star quality rating on Telegram. Site quality, brief quality, anything off.
7 days later: a check-in. 🔥 Strong interest / 👍 Some / 😐 None / 🗑 Kill. Real market response from real people who saw the site.
Hot signals trigger a structured debrief. What worked? What resonated? That becomes the v2 brief, or a funded product.
All ratings and signals save to shared memory. Every agent recalls them at the start of each run. The pipeline learns what works, and what doesn't.
The feedback loop is what separates a pipeline from a machine that learns. Each rated POC makes the Creative Director's seed enrichment more calibrated, the PE Firm's scoring more predictive, and the whole system more likely to surface the ideas that actually become products.
Why It Matters
The old way costs a fortune. This doesn't.
Most ideas die not because they're bad, but because validating them is expensive. We changed that math.
"We're not replacing human judgment. We're running it at a scale and speed no human team could match. So the ideas that deserve to exist get a real shot."
Each AI agent has a single job and does it the way a specialist consultant would. The PE Firm scores through nine forced-lens sections, then lands on a verdict; the Devil's Advocate tries to tear the thesis apart with evidence. The Product Designer outputs a real BOM before anyone generates a 3D model. The Copywriter reads customer pain quotes before writing a headline. The result is an honest evaluation and a real demo deployment. Not a pitch deck.
See what the pipeline outputs.
Every demo above was built by these agents through this pipeline. Click any card to open the demo site and the evaluation notes behind it.
View pipeline output →